Elasticsearch 是一个基于 Lucene 的搜索引擎,采用 Java 语言编写,使用 Lucene 构建索引,提供索引功能。Elasticsearch 的目的是让全文搜索变得更简单,开发者可以通过简单明了的 RESTFul API 轻松实现搜索功能,而 不必去面对 Lucene 的复杂性。
[TOC]
数据分类与搜索方法
数据分类
- 结构化数据:指具有固定格式或有限长度的数据,如数据库、元数据等。对于结构化数据,我们一般都是可以通过关系型数据库(MySQL、Oracle 等)去存储和搜索,也可以建立索引,通过 B 树等数据结构快速搜索数据。
- 非结构化数据:全文数据,指不定长或无固定格式的数据,如:邮件、word 文档等。对于非结构化数据,主要有两种搜索方法:顺序扫描法和全文搜索法。
搜索方法
- 顺序扫描法:从头到尾按顺序查找,文档内容几乎被通读了一遍。如果数据量大的话,那么这种方法效率会非常低。
- 全文搜索法:将非结构化数据的一部分信息提取出来,重新组织,使其变得有一定结构,然后对这些有一定结构的数据建立索引,从而达到了搜索高效的目的。
全文搜索引擎
根据百度百科中的定义,全文搜索引擎是目前广泛应用的主流搜索引擎。它的工作原理是通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序根据索引进行查找,并将结果反馈给用户。常见的搜索引擎有 Lucene、Solr、Elasticsearch。
Elasticsearch 的优点
- 可扩展:Elasticsearch 的横向扩展非常灵活,当数据规模比较小的时候可以使用小规模的集群。随着数据的增长,需要更大的容量和更高的性能,此时只需添加更多的节点,Elasticsearch 的自动发现机制会识别新增的节点并重新平衡地分配数据。
- 全文检索:Elasticsearch 在后台使用 Lucene 来提供最强大的全文检索功能。
- 近实时的搜索和分析:数据进入 Elasticsearch,可以达到近实时搜索。除了搜索,Elasticsearch也可以进行聚合分析操作。
- 高可用:高可用主要体现在容错机制上,Elasticsearch 集群会自动发现新的或失败的节点,重组和重新平衡数据,确保数据是安全的和可访问的。
- RESTFul API:几乎所有的操作都可以通过 RESTFul API 使用 JSON 基于 HTTP 请求来实现,客户端也可以使用多种语言。
Elasticsearch 与 Solr 的比较
当单纯的对已有数据进行搜索时,Solr更快。
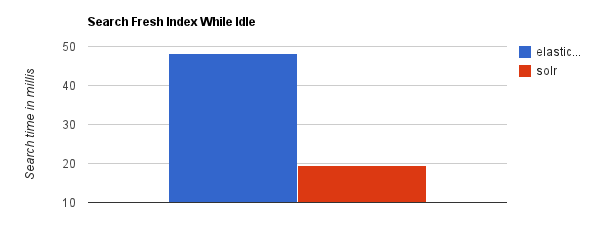
当实时建立索引时, Solr会产生io阻塞,查询性能较差, Elasticsearch具有明显的优势。
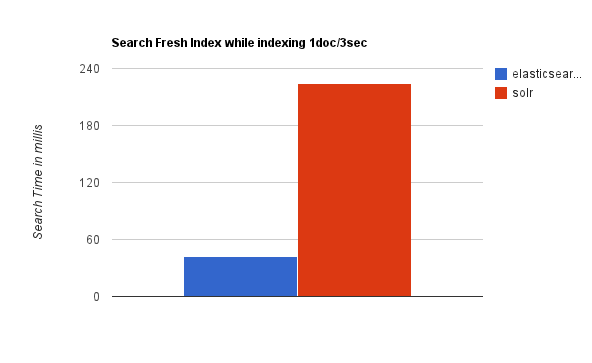
随着数据量的增加,Solr的搜索效率会变得更低,而Elasticsearch却没有明显的变化。
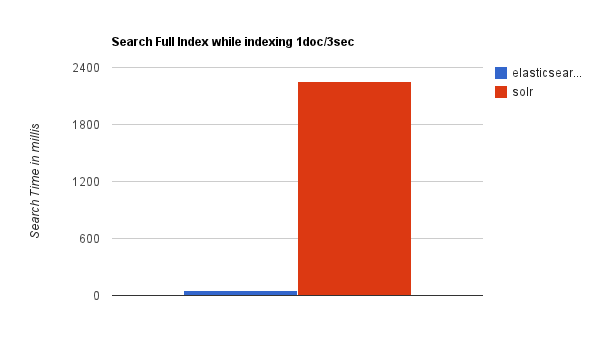
Solr 在建立索引或数据量大的时候,索引效率不高。而 Elasticsearch 则比较稳定。
环境/版本一览:
- 开发工具:Intellij IDEA 2019.1.3
- springboot: 2.1.7.RELEASE
- jdk:1.8.0_171
- maven:3.3.9
- elasticsearch:6.2.2
1、pom.xml
1 | <dependencies> |
2、application.yml
1 | spring: |
3、entity
1 | package com.fatal.entity; |
4、respoitory
1 | package com.fatal.repository; |
5、component
1 | package com.fatal.component; |
6、Test
TransportClientTests.java
1 | package com.fatal.client; |
CityRepositoryTests.java
1 | package com.fatal.repository; |
ElasticsearchTemplateTests.java
1 | package com.fatal.template; |
7、测试
启动 ES,并且启动 head 插件。这里的 ID 都是 ES 自动生成的
批量添加
执行 CityRepositoryTests.saveAll()
查看控制台

你会发现,id 都是 null。郁闷呢。其实这里不影响使用。查询的时候它就给你显示出来了。
看看 head 插件
索引信息
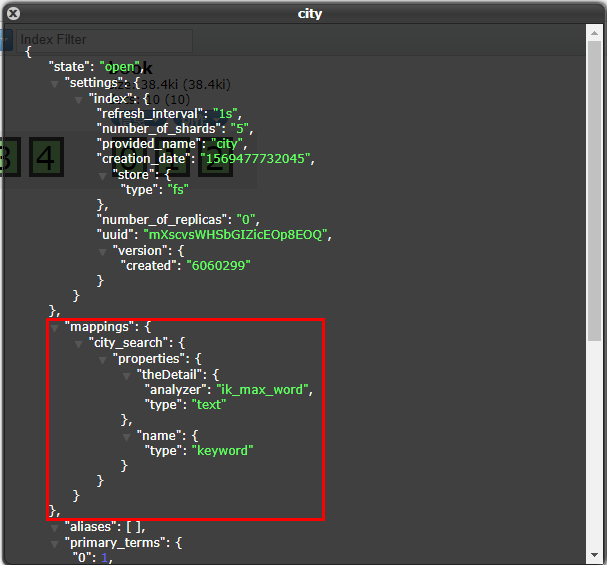
数据浏览
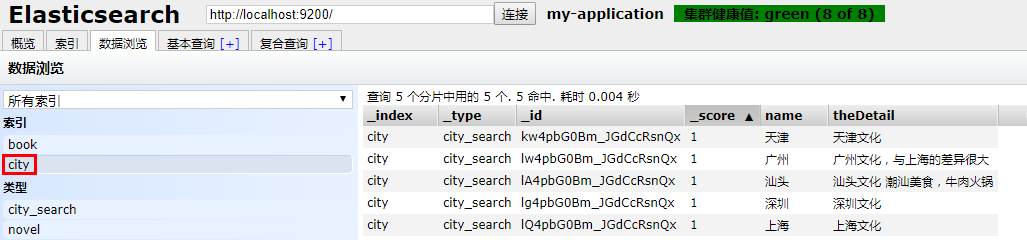
更新
执行 CityRepositoryTests.updateTest()
查看控制台

看看 head 插件
每更新一次,版本号 + 1
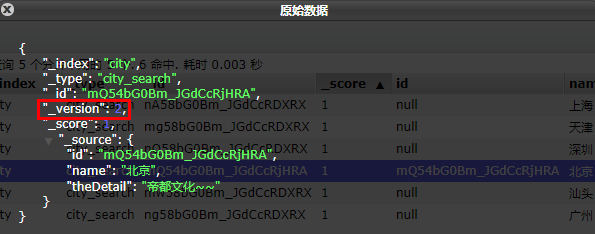
查询
执行 CityRepositoryTests.compoundConditionalQueryTest()
查看控制台

高亮查询
执行 ElasticsearchTemplateTests.highLightTest()
查看控制台

其他…
自己测
笔记
常用注解和枚举
@Document
1 | public Document { |
@Field
1 | public Field { |
FieldType 的 text 和 keyword 的区别
- text :如果一个字段是要被全文搜索的,比如邮件内容,产品描述,新闻内容,应该使用 text 类型。设置 text 类型之后,字段内容会被分析,在生成倒排索引以前,字符串会被分词器分成一个一个词项。text 类型的字段不用与排序,很少用于聚合(termsAggregation 除外)。
- keyword :适用于索引结构化的数据,比如 email 地址、主机名、状态码和标签,通常用于过滤(比如查找已发布在微博中 status 属性为 published 的文章)、排序、聚合。类型为 keyword 的字段只能用于精确值搜索,区别于 text 类型。注意,keyword 是不参与分词的。
问题
Lombok 的 @Accessors(chain = true) 与 PropertyUtils 有冲突。具体体现在同时使用的话,PropertyUtils.setProperty(final Object bean, final String name, final Object value) 方法解析不了 setter 方法,进而报错 NoSuchMethodException…。
原因如下:PropertyUtils 解析时,要求 settter 方法不能有返回值。
@Builder 注解加到类上时程序找不到类的无参构造方法
原因:加 @Builder 之后默认生成一个 default 级别的全参构造器,所以无参构造器就不会自动生成了。
如果只加 @NoArgsConstructor ,那么 @Builder 就不会生成全参构造器,这时候编译就不会通过,所以解决方法时,使用 @Builder 的时候,带上 @NoArgsConstructor 和 @AllArgsConstructor 即可。
参考资料
elasticsearch技术解析与实战
从Lucene到Elasticsearch:全文检索实战
和我一起打造个简单搜索之SpringDataElasticSearch关键词高亮
总结
SpringBoot的知识已经有前辈在我们之前探索了。比较喜欢的博主有:唐亚峰 | Battcn、方志朋的专栏、程序猿DD、纯洁的微笑。对这门技术感兴趣的可以去他们的博客逛逛。谢谢他们的分享~~
以上文章是我用来学习的Demo,都是基于 SpringBoot2.x 版本。
源码地址: https://github.com/ynfatal/springboot2-learning/tree/master/chapter32