Redis 是一个高性能的 key-value数据库。它有五种数据类型,分别为 string(字符串)、list(列表)、set(集合)、zset(有序集合)、hash(哈希表),这些数据类型的所有操作都是原子性的。由于 Redis 有多种数据类型,而且性能特别高,所以能用的场景也很多,包括购物车。
注意:
Redis是使用ANSIC语言编写的,ANSI 是一种基于ASCII扩充的编码字符集。以下说 32 字节,在这里可以放 32 个字母。
[TOC]
为什么选择 Redis 做购物车?
存储购物车当然得使用数据库,数据库分为关系型数据库(这里用 Mysql)和非关系型数据库(这里用 Redis),我们应该怎样选择?
我们先从购物车Item的数据模型说起,百度了一下,网上的很多方案,大部分都有一个缺点,就是将Sku图片等等属于Sku的数据(以下称为“共有数据”;在他们的数据库设计中,这些字段都属于冗余字段)放在购物车Item的数据模型中,购物车每加入一个商品,都会有这些重复的数据;如果有一万个用户的购物车都有这种Sku,那么这些共有数据将会重复 9999 次。那如果还有一万种Sku呢?那数据库岂不是存放了大量的垃圾数据!这只是缺点之一。如果你也这么做的话,那你应该会发现,购物车这个模块,你还不能很好的使用 cache(可以参考后面的方案对比)。他们设计这样的数据模型不仅浪费数据库空间,而且性能上也不怎么样(以查询 mysql 和查询 redis 做对比)。
那么,既然是 共有数据,我们就应该考虑重复使用,购物车Item的话,数据模型可以包括五部分:用户ID,SkuID,店铺ID,商品数量,加入购物车时间,这些数据都是购物车的核心。其中,加入购物车时间是为了展示的时候按照时间排序,最新的排在前面。那些需要展示的共有数据,我们则是从 sku 的cache 中取;查询购物车列表的时候,我们也可以约定每次下拉刷新 16 条记录,然后通过遍历的方式从缓存中拿到这 16 条需要展示的数据。这种方式是不是性能更好,可以大大地减少 mysql 的负担。当然,我们系统的 mysql 一般都存储了很多数据,忍辱负重,购物车当然可以存放在 mysql 中,但这样做如果用户太多,对 mysql多少还是有些压力 。那如果我们选择将购物车放在 Redis 中呢?从性能上讲,是不是达到了最优的策略?!😆
方案对比
接下来不讨论
Mysql方案数据库设计的缺点(需要看上边)
对购物车的操作(可分为以下五种):
1)加入一个新的 Sku
2)原有的 Sku 数量加 n 减一(当然,在数量允许范围内)
3)指定的 Sku 从购物车移除(购物车减少一种 Sku)
4)清空购物车
5)查看购物车
前四项操作与第五项操作的触发关系:
1)必定会触发5)。加入之后肯定会去看购物车然后下单,除非你加入的时候不想买(这种情况不讨论)。
2)前端可以做处理,向后端的请求只要返回成功,前端就保持 count 不变,不刷新购物车,这样就不会触发5)。
3)同2)。
4)一般不会触发5)。
Mysql 方案
购物车(商品项列表)加层缓存。(缓存影响因素在用户)
缺点:
- 用户体验相对较差
- 有一定概率会出现数据库崩溃(人为触发缓存清除)
- 支持的用户量级别取决于单体
Mysql能支持的并发量(并不是指支持的用户量等于数据库支持的并发量) - 搞
Mysql集群也是强弩之末,支持的用户量级别只能增加 n 倍,n 表示集群的数目节点数
解析:
执行前四项操作的任何一项,都会造成购物车数据改变,这时候购物车缓存需要被清除(换句话说,为购物车加的缓存,只对用户不改变购物车数据的时候有效),如果用户选择这时候再次刷新购物车,那么请求会直接到达数据库,响应相对缓存会慢很多,用户体验较差。如果多个用户同时处于这种状态(执行过前四项操作之一,并且都选择刷新购物车,以下的这种状态也是指这个意思),那么当同时处于这种状态的用户量达到一定程度时,会对数据库造成很大的负担,严重时数据库直接挂了。其实这和缓存雪崩类似,区别是雪崩是数据库存在大量过期时间相同的缓存数据,缓存过期后会自动清除;而当前这种方案的话,或许缓存已经设置为永久不过期,但是一定会出现人为造成缓存清除(执行前四项操作之一)。可能有人觉得大量用户处于这种状态的概率特别小(其实,用户量比较大的时候,这个概率就特别大了),我则是认为我们不能因为概率小就忽视它,缓存雪崩的造成原因,即数据库存在大量过期时间相同的缓存数据出现的概率也是特别小的,但是往往有时候就是这种概率小的事件,给我们带来非常头疼的问题。
Redis 方案
指本文方案
购物车(商品项列表)需要展示的数据直接从 Sku 缓存拿,只要 Sku 不改变,Sku 缓存就一直都在。(缓存影响因素不在用户,而在于意外)
优点:
- 用户体验非常好(数据基本都放
Redis) - 和
Mysql方案同一级别的用户量,数据库崩溃的概率基本为 0 - 出现数据库崩溃的概率有多小(健壮性好),支持的用户量级别就有多大
Mysql集群的环境下,根据用户量级别配置对应的节点数,数据库崩溃的概率基本为 0
不存在了上述 Mysql 方案的缺点,执行前四项操作的任何一项,都不会动到缓存(Sku 缓存)。可能有人觉得,Sku 缓存也可能被清除,也有极小的概率造成数据库挂了。Sku 缓存大量被清除的情况一般是不存在的,通过后台管理系统对 Sku 修改之后一定会对该商品进行 Sku 列表的查询(查看是否操作成功嘛),所以 Sku 缓存会立即恢复;除非有人直接用 Redis 客户端 或者 命令 手动删除了缓存,这就另当别论了。其实就算真的出现 Sku 缓存全被清除了,大量用户同时选择刷新购物车,也没事,这里的条件还不足以触发某轮①出现上万次数据库访问②,而且Sku 在被刷新一次后它就被缓存起来,最多只会造成部分用户体验差点(到数据库查询 Sku 的那部分用户),没什么别的影响,健壮性在这里体现出来了。
①:某轮。看下图,比如购物车 1 的第 1 个
Sku,购物车 2 的第 3 个Sku,购物车 3 的第 2 个Sku,购物车 a 的第 b 个等等好多Sku构成一轮查询同时查询数据库。②:触发条件很苛刻。大量查询购物车的请求同时来到查询方法,方法中会执行一条
Redis命令,其时间复杂度为O(1),又因为Redis是单线程,所以这条Redis命令在这里起到了队列的作用。具体参考方法com.fatal.service.impl.ShopCartServiceImpl#shopCartGrouping。所以这里除非Redis集群节点数很多而且用户量也是一个非常大的数字,不然不可能有上万并发到数据库。
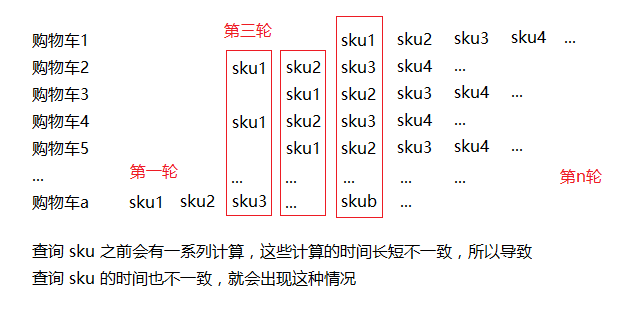
如果同时存在:有人把 Sku 缓存全部删了;大量用户同时选择刷新购物车(1);这些用户购物车的某轮①数据库查询达到上万次(2),并且前 n 轮都不存在相同的 Sku;其他用户刷新购物车(购物车含有该轮查询的 Sku)发生在(1)之后;其他用户执行前两项操作(购物车含有该轮查询的 Sku)发生在(1)之后(前两项操作做了校验,判断 Sku 是否存在);其他用户在逛商城时浏览商品(含有该轮查询的 Sku)发生在(1)之后(商品展示的规格数据会根据是否有库存判断该 Sku 是否可以点击);… 。数据库还真的有可能挂了。
抱歉,打搅了。
真的会出现这种情况的话,只能从硬件上解决问题,因为软件已经达到极限了。某轮①数据库查询达到上万次,而且前 n 轮都不存在相同的 Sku,当这个概率很大的时候,那说明这个商城的规模已经特别特别大了,它肯定很有钱,Mysql 搞个集群什么的肯定没什么压力,可以通过这种方式来解决问题。Mysql 方案也可以搞集群,但是它和 Redis 方案两者支持的用户量完全不在一个数量级上。(两种方案数据库崩溃的概率对比,Mysql 方案得配多少个 Mysql 集群节点才能将支持的用户量提到 Redis 方案一个级别啊,而且就算支持的用户量上来了,那用户体验还是没改变。)
多规格的商品 Sku
SKU = Stock Keeping Unit(库存量单位),sku 可以理解为具有具体规格的商品。
同一种商品存在不同的规格参数值,包含这些值的属性又称为 sku 属性,因为它决定了 SKU 的绝对数量。
比如40码白色帆布鞋,40与白色都属于帆布鞋的规格参数值。
而 38,39,40 这些值都属于码数,白色,黑色,蓝色属于颜色,这里的码数和颜色就属于帆布鞋的sku属性。38,39,40 与 白色,黑色,蓝色都是 sku 的属性选项(展示的时候叫规格参数)。
当商品比较简单的时候,后面笔记中的 sku 也可以用goods代替。
为什么选择 hash 来实现?
如果使用 Redis 做购物车,有多少种数据类型可以选呢?
下面一个
购物车skuDTO对应一个对象{}
第一:如果选择 string 呢?
key:userId;value:[{skuId: xxx, count: xxx, intoTime: xxx},...]选择 string 的话,每个用户的购物车对应一个 string 对象,value 存的是
购物车skuDTO集合。string 底层编码有int,raw,embstr,由于我们 value 存的是字符串值的长度一般都大于 32 字节,所以 string 会选择使用raw编码。
第二:如果选择 set 呢?
key:userId;value:{skuId: xxx, count: xxx, intoTime: xxx}选择 set 的话,每个用户的购物车对应一个 set 对象, value 存的是 单个
购物车skuDTO。set 底层编码有intset,hashtable当集合对象同时满足以下两个条件时,对象使用
intset编码;不能满足则使用hashtable编码。- 集合对象保存的所有元素都是整数值;
- 集合对象保存的元素数量不超过 512 个。
由于 value 存的不是整数值不满足第一个条件,所以 set 使用
hashtable编码。
第三:如果选择 zset 呢?
key:userId;value:{skuId: xxx, count: xxx}选择
zset的话,每个用户的购物车对应一个zset对象, value 存的是购物车skuDTO,score 存的是加入购物车的时间,让zset帮我们排序。zset的底层编码是ziplist和skiplist。当有序集合同时满足以下两个条件时,对象使用
ziplist编码;不能满足则使用skiplist编码。- 有序集合保存的元素数量小于 128 个;
- 有序集合保存的所有元素成员的长度都小于 64 位。
由于我们将
zset的元素个数限制在120之内(这是淘宝购物车单种商品的上限数量,参考购买指南),满足第一条件,不过元素值长度会超过 64字节,所以zset使用skiplist编码。
第四:如果选择 list 呢?
key: userId;value:{skuId: xxx, count: xxx}选择 list 的话,每个用户的购物车对应一个 list 对象,value 存的是
购物车skuDTO。list 的底层编码是ziplist和linkedlist。当列表对象同时满足以下两个条件时,对象就会使用
ziplist编码;不满足则使用linkedlist编码。- 列表对象保存的所有字符串元素的长度都小于 64 字节;
- 列表对象保存的元素数量小于 512 个。
从 3.2 版本开始,
Redis对列表对象的底层编码做了改造,使用quicklist替代之前两种,它是ziplist和linkedlist的混合体,它会安装插入顺序排序。
第五:如果选择 hash 呢?
key:userId;field:skuId;value:count选择 hash 的话,每个用户的购物车对应一个 hash 对象,field 存的是
skuID,value 存的是购物车单种sku总量。hash 的底层编码是ziplist和hashtable。当哈希对象同时满足以下两种条件时,对象使用
ziplist编码;不能满足则使用hashtable编码。- 哈希对象保存的所有键值对的键和值的字符串长度都小于 64 字节;
- 哈希对象保存的键值对数量小于 512 个。
首先,field 的长度肯定不会超过 64 字节,value 存放的是购物车
单种sku总量,这个数量我们系统会默认给一个上限(如:10000),第一个条件可以满足;其次,购物车 sku 的种类我们可以限制在 120 之内(这个数字你随意,在 512 之内即可),第二个条件也可以满足。两个条件都能同时满足,使用 hash 做购物车的时候,hash 对象(的 field)使用ziplist编码,它会按照插入顺序排序。这也是我们没有存加入购物车时间的原因,它已经帮我们保留了顺序,所以这个时间就多余了。
相比这五种选择,除了hash,其它的数据类型,都需要 get 出来计算后 set 回去,有的还需保存加入购物车时间 来排序。用来做购物车还是可以的,就是有点小麻烦,也没有充分利用 Redis 的数据类型(充分利用的话性能有很大的优势);而 hash 就不一样了,我们满足它以 ziplist编码的条件,它就是有序的了 ,不需要额外计算,可以直接使用 Redis 命令来完成对购物车的维护,性能上无疑达到了最优,这简直就是 Redis为购物车专门定制的一套 完美的方案 嘛。:heart_eyes:
相关命令时间复杂度
| Spring Data Redis | Redis 命令 | Redis 命令时间复杂度 | 最终时间复杂度 |
|---|---|---|---|
| HV get(K key, Object hashKey) | hget key field |
O(1) |
O(1) |
| void put(K key, HK hashKey, HV value) | hset key field value |
O(1) |
O(1) |
| Long size(K key) | hlen key |
O(1) |
O(1) |
| Long increment(K key, HK hashKey, long delta) | hincrby key field increment |
O(1) |
O(1) |
| Map<HK, HV> entries(K key) | hgetall key |
O(N) N是hash元素个数 |
购物车Sku种类限制最多120,所以最坏的情况下是O(120)。O(1~120) |
| Cursor<Entry<HK, HV>> scan(K key, ScanOptions options) | hscan key cursor [MATCH pattern][COUNT count] |
O(1) |
O(1) |
| Long delete(K key, Object… hashKeys) | hdel key [key …] |
O(N) N是被删除的field的数量 |
购物车Sku种类限制最多120,所以最坏的情况下是O(120)。O(1~120) |
| Boolean delete(K key) | del key [key …] |
O(N) N是被删除的key的数量,key 可以是任何类型;比如hash,删除一个key的时间复杂度也是O(1)。 |
清空购物车,删除一个hash,所以时间复杂度是O(1) |
- 用
hscan取代hgetall优化性能hdel删除field的个数一般不会很大。
Redis 底层编码 ziplist
ziplist 重点:
- 压缩列表是一种为节约内存而开发的的
顺序型数据结构。(这是重点) - 压缩列表被用作
列表键和哈希键的底层实现之一。 - 压缩列表可以包含多个节点,每个节点可以保存一个字节数组或者整数值。
- 添加新节点到压缩列表,或者从压缩列表中删除节点,可能会引发连锁更新操作,但这种操作出现的几率不高。
因为连锁更新在最坏的情况下需要对压缩列表进行 N 次空间重分配操作,而每次空间重分配操作的最坏复杂度为 O(N),所以连锁更新的最坏复杂度为 O(N²)
- 首先,压缩列表里要恰好有多个连续的、长度介于 250 字节至 253 字节的节点,连锁更新才有可能被引发,在实际中,这种情况并不多见;
- 其次,即使出现连锁更新,但只要被更新的节点数量不多,就不会对性能造成任何的影响:比如说,对三五个节点进行连锁更新是绝对不会影响性能的。
Redis 的 hash 选择ziplist编码的第一个条件要求:所有的 field 和 value 值的长度都小于64字节,64 远小于 250,所以我们可以不用担心 Redis 的 hash 会出现连锁更新。
hash 实现购物车
使用 Redis 的 hash 数据类型实现购物车,每个用户的购物车则对应一张哈希表。哈希表每个元素的 field 存储skuID,value 存储订购sku的数量。购物车中单个sku订购的数量需要有上限,系统默认对加入购物车的sku 统一设置了上限(例如:10000),卖家可以在这个上限的范围之内再设置一个小于系统默认值的上限(例如:200);购物车的sku的种类也需要有上限,系统默认对购物车的商品种类设置了上限,例如:120,这个数字是淘宝的默认值,当用户的购物车有120种sku的时候,它不能再添加新的sku进购物车。
Redis 做购物车,这里选择了 hash 类型,每个用户的购物车对应一个 hash 对象。如下:
| key | field | value |
|---|---|---|
| userId | skuId |
count |
| 用户ID | skuID |
单种sku总量 |
这是这次选择的方案,直接用 Redis 命令保存,移除(部分),清空,查询购物车,前三个不需要额外的计算。
由于购物车需要保留两种顺序,一种是添加的顺序,另一种是计算后展示的顺序(同一个店铺的商品,只要有一个是刚添加的,那么就算其他的是最早添加,这个店铺也是排在购物车的第一位),所以这里还需要设计一张哈希表。(记录 shopId 是为了后边分组)
| key | field | value |
|---|---|---|
| userId | skuId |
shopId |
| 用户ID | skuID |
店铺ID |
这个哈希表不是必要的。你也可以去掉,但是去掉之后,每次查询购物车要拿到和店铺的关系数据(就是这张哈希表)都得通过遍历拿出所有 Sku 数据,虽然每次拿使用的 get 命令的时间复杂度是 O(1),但是购物车Sku种类限制最多有120,所以最坏的情况下也是 O(120),和使用 hgetall 效果差不多;加了这个哈希表就不一样了,通过简单的维护,后边需要拿和店铺的关系数据的时候,直接使用时间复杂度为 O(1) 的 hscan 命令即可,所以建议加上它。
环境/版本一览:
- 开发工具:Intellij IDEA 2019.1.3
- springboot: 2.1.7.RELEASE
- jdk:1.8.0_171
- maven:3.3.9
- mysql-connector-java:5.1.47
1、pom.xml
1 | <dependencies> |
2、application.yml
1 | spring: |
3、sql
1 | /* |
4、config
配置两部分:( Json 序列化)
- 自定义
RedisCacheConfiguration的序列化方式 - 自定义
RedisTemplate,以及key,value,hashKey,hashValue的序列化方式。hashKey,hashValue存储的是 Long 类型或者 Integer 类型,所以序列化方式可以选择GenericJackson2JsonRedisSerializer。
1 | package com.fatal.config; |
5、common
5.1、constants
1 | package com.fatal.common.constants; |
5.2、enums
ResponseEnum.java
1 | package com.fatal.common.enums; |
StatusEnums.java
1 | package com.fatal.common.enums; |
5.3、exception
1 | package com.fatal.common.exception; |
5.4、handler
自定义全局异常处理器。
1 | package com.fatal.common.handler; |
5.5、utils
1 | package com.fatal.common.utils; |
6、entity
记得实现 Serializable,后面自定义的RedisTemplate保存的 value 只要实现 Serializable 接口即可。(Spring Cache 缓存的对象不需要实现 Serializable 接口)
1 | package com.fatal.entity; |
7、dto
位于
controller和service两层,不包括RedisTestDTO,它只是测试用的。
RedisTestDTO.java
测试数据类型的底层数据结构
1 | package com.fatal.dto; |
ShopCartDTO.java
对应 ShopCartVO,属性完全一样的。
1 | package com.fatal.dto; |
ShopCartSkuDTO.java
与 ShopCartItemDTO 的区别就是多了 shopId 和shopName,这两个属性用于后边分组和展示;少了 count 属性,这个属性不在 ISkuService 对外 DTO 的范畴中。
1 | package com.fatal.dto; |
ShopCartItemDTO.java
对应 ShopCartItemVO,属性完全一样的。
1 | package com.fatal.dto; |
8、vo
位于
controller层,用在视图展示,可以将一个或多个DTO改造成需要展示的数据放在VO中。
ShopCartVO.java
1 | package com.fatal.vo; |
ShopCartItemVO.java
1 | package com.fatal.vo; |
9、repository
1 | package com.fatal.repository; |
10、service
ISkuService.java
1 | package com.fatal.service; |
IShopCartService.java
1 | package com.fatal.service; |
SkuServiceImpl.java
1 | package com.fatal.service.impl; |
ShopCartServiceImpl.java
1 | package com.fatal.service.impl; |
11、controller
1 | package com.fatal.controller; |
12、Application
加两个配置:
- 启用缓存
- 暴露代理
1 | package com.fatal; |
13、Test
ShopCartServiceImplTest.java
1 | package com.fatal.service.impl; |
RedisTests
1 | package com.fatal.redis; |
14、测试
由于数据不多,下面的测试设置了 pageSize 为 4 方便看。
说明
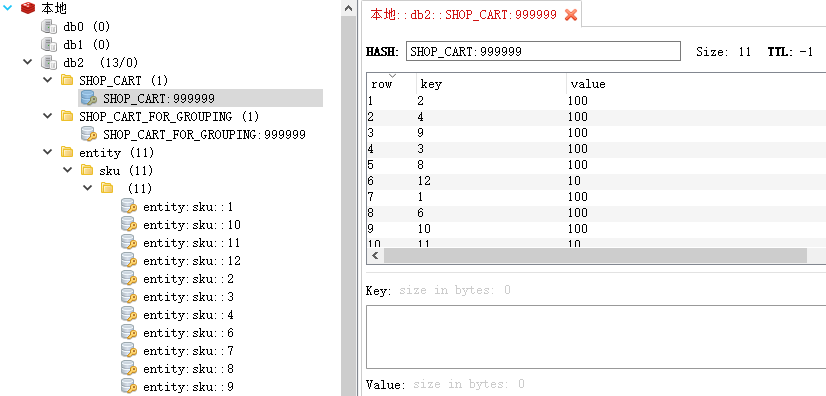
SHOP_CART:购物车,放SkuId以及它对应的数量SHOP_CART_FOR_GROUPING:用于分组的购物车,放SkuId及对应的店铺ID(后续需要按店铺分组)SORT_SHOP_CART:排序购物车,经过分组和摊平操作之后的SkuIds(缓存)SHOP_CART_PAGE:购物车分页所包含的SkuIds(根据排序购物车计算得出)(缓存)entity:sku:实体(缓存)
初始化数据
运行 ShopCartServiceImplTest.init()
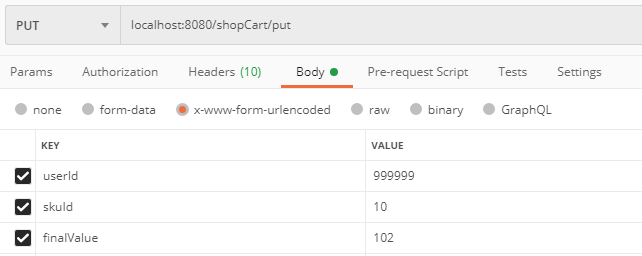
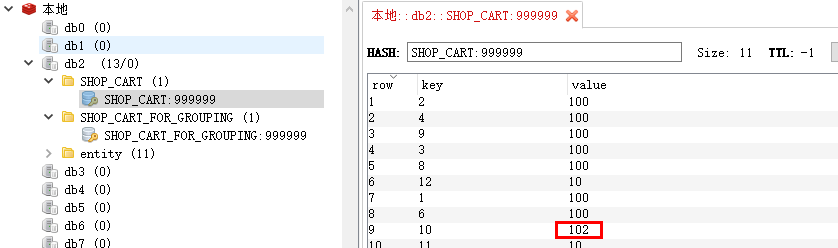
保存购物车
不管是四项操作中的哪一项,只要把
count最终值作为第三参数传给后台即可
访问 localhost:8080/shopCart/put,参数自己填充
Redis 视图界面:
进入购物车
访问 localhost:8080/shopCart?userId=999999
响应:
1 | 3 // 总页数 |
购物车列表
从上个接口可以得出现在有3页
首先看看第一页
访问 localhost:8080/shopCart/shopCarts?userId=999999¤tPage=1
先看看 Redis 视图化界面:
SORT_SHOP_CART 中 skuId 的顺序:

1 | [7,6,4,11,10,8,9,1,12,3,2] |
再来看看SHOP_CART_PAGE第一页的skuId:
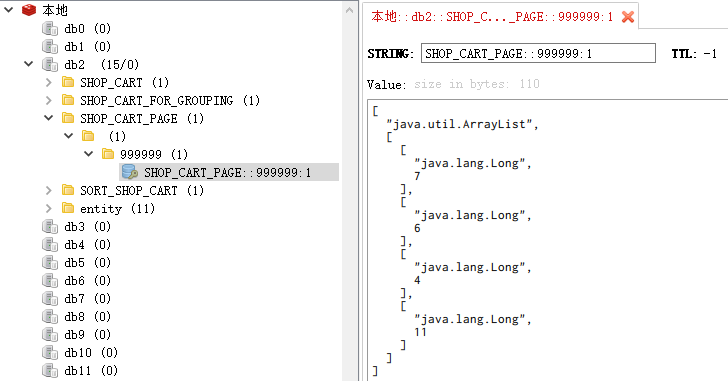
1 | [7,6,4,11] |
再来看看响应的数据是否一致:
从这里可以看出,skuId 为 7 的 sku 是最新添加的,所以,它所属的店铺信息排在最前边。
1 | [ |
debug 了 ShopCartServiceImpl#shopCarts 的方法,下图是该方法的第三步的流程图。
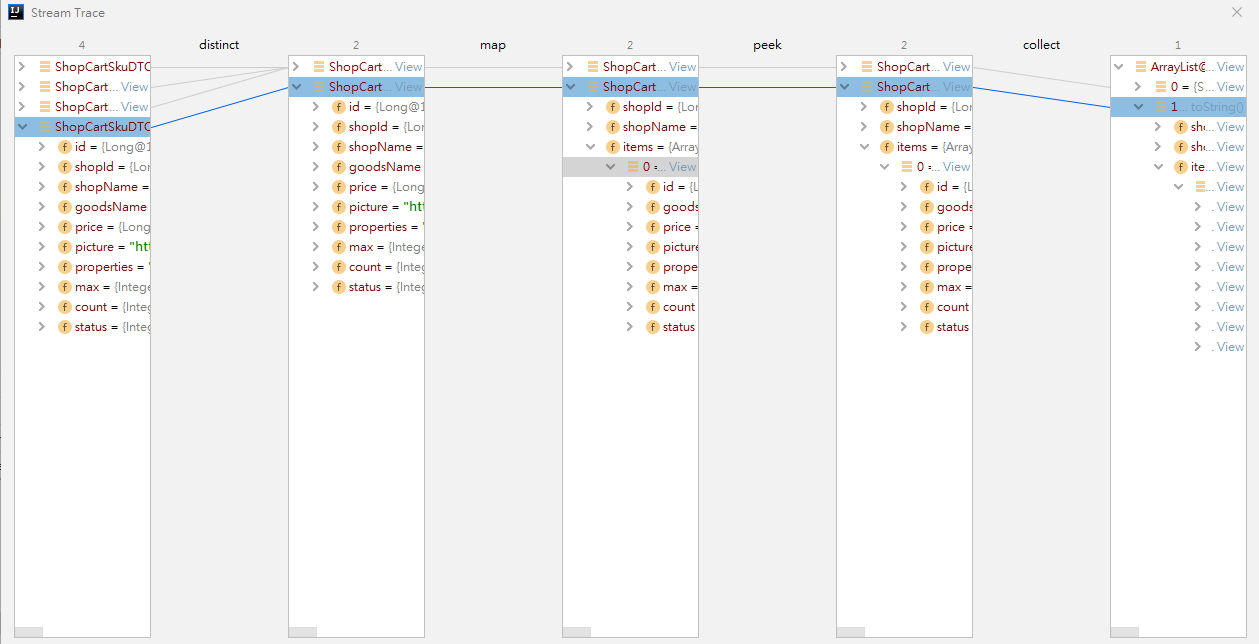
其实,按照
stream的方式在map之后 items 是没有数据的,不过 idea 它这里显示的是现在时,也就是当前状态,所以peek之后的数据在这里也展示了。
接着来看看第二页
访问 localhost:8080/shopCart/shopCarts?userId=999999¤tPage=2
还是先看 Redis 视图化界面:
你会发现,SHOP_CART_PAGE第二页的skuId也正常
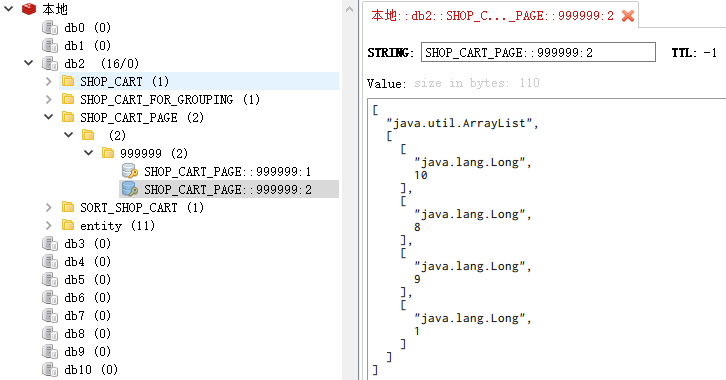
1 | [10,,8,9,1] |
再来看看响应的数据是否一致,发现数据也正常。
1 | [ |
看看最后一页
访问 localhost:8080/shopCart/shopCarts?userId=999999¤tPage=3
刷新下 Redis 视图化界面,SHOP_CART_PAGE第三页的 skuId也正常:
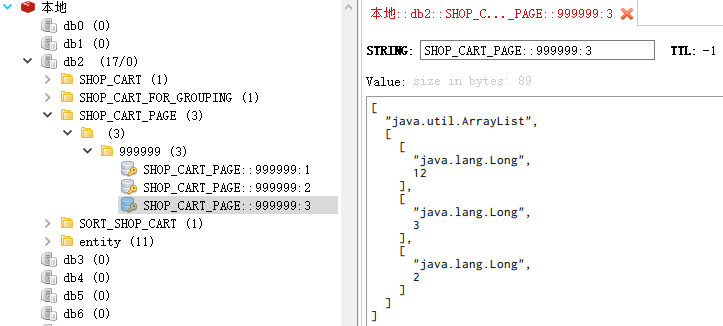
1 | [12,3,2] |
再来看看响应的数据,发现都正常…
1 | [ |
从购物车移除(部分种类商品)
访问 localhost:8080/shopCart/remove,参数自己填充(7,10,3)
Redis 视图界面:
你会发现 SORT_SHOP_CART、SHOP_CART_PAGE这两组缓存数据被清理了
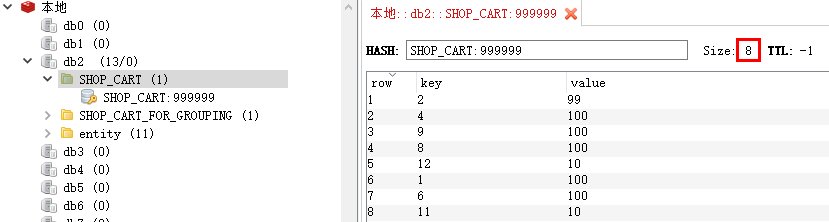
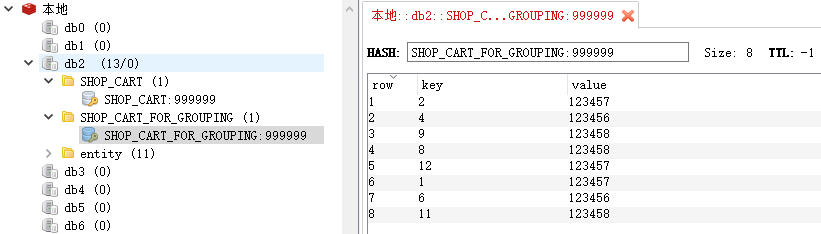
并且 SHOP_CART 和 SHOP_CART_FOR_GROUPING的数据也更新了
再测试下查询,看看数据是否正常
先访问localhost:8080/shopCart?userId=999999,得到的总页数为:2
接着分别访问localhost:8080/shopCart/shopCarts?userId=999999¤tPage=1和currentPage为 2的。
Redis 视图化界面:
SORT_SHOP_CART:

SHOP_CART_PAGE的第一页:
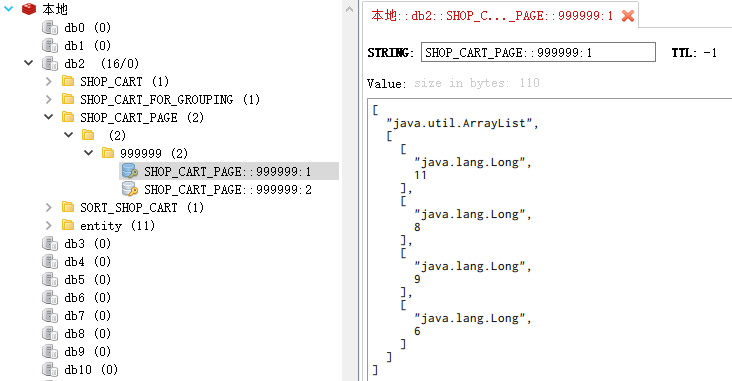
1 | [11,8,9,6] |
SHOP_CART_PAGE的第二页:
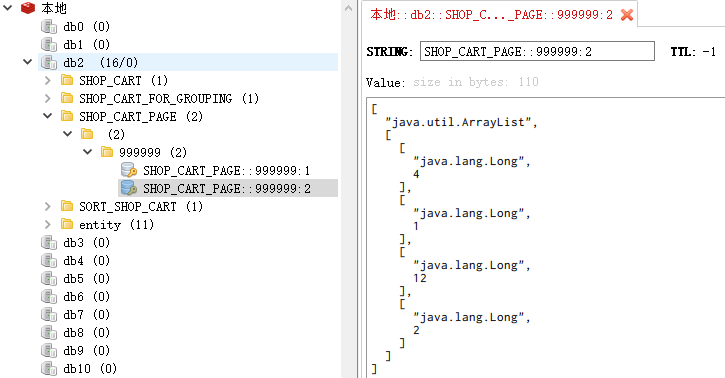
1 | [4,1,12,2] |
再看看响应
第一页响应:
1 | [ |
第二页响应:
1 | [ |
响应数据跟缓存数据一致。
清空购物车
访问 localhost:8080/shopCart/clear,参数自己填充
Redis 视图界面:
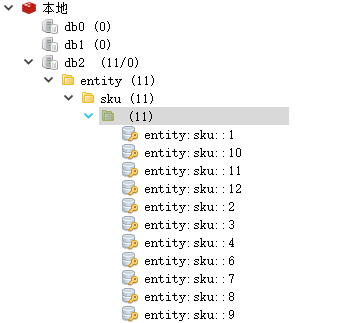
只剩下实体的缓存
展示
首先,前后端约定每次下拉最多刷新多少sku,这篇笔记以 16 为例子。
前端拿 购物车列表 直接展示即可。
临界值
第一种情况:假设现在用户购物车有 30 个 sku。用户第一次查出了16条记录中,最后一条记录属于店铺 Fatal Shop。当用户向下拉的时候,前端将会拿接下来的14个skuId,问题来了,第二次这 14 个 sku 的前两个 sku也属于店铺 Fatal Shop,这是出现以下的数据:
1 | // 这是进入购物车后首次展示的16个sku. |
那么,这时候需要合并。首先,刷新之前先拿到上一页最后一个店铺id。刷新之后,与下页的第一个店铺id进行比较,如果相等,则将下页第一个店铺的items数据追加在上一页最后一家店铺的items中,然后下页其它店铺的数据正常显示;如果不相等,直接渲染即可。
查看 Redis 底层实现
只举例
zset,其它根据需要自己测。
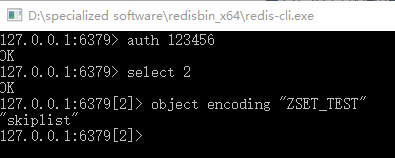
执行 RedisTests.zSetTest() 方法
使用 redis-cli 输入命令
1 | redis> object encoding "ZSET_TEST" |
显示如下图
笔记
问题:使用Json方式序列化和反序列化,LocalDateTime 没有无参构造怎么处理?
解决方式:
在该属性上面添加两个注解,分别制定序列化器和反序列化器。
1 | (using = LocalDateTimeDeserializer.class) |
查看 Redis 底层实现的命令
1 | object encoding [key] |
Redis 的增量式迭代
SCAN 命令及其相关的 SSCAN, HSCAN 和 ZSCAN 命令都用于增量迭代一个集合元素。
- SCAN 命令用于迭代当前数据库中的
key集合。 - SSCAN 命令用于迭代
SET集合中的元素。 - HSCAN 命令用于迭代
Hash类型中的键值对。 - ZSCAN 命令用于迭代
SortSet集合中的元素和元素对应的分值
增量式迭代:可以在迭代的过程中对集合进行元素操作,包括
增加、修改、删除。概念具体可以参考(从 scan 命令 摘取)
- 这类增量式迭代命令来说,有可能在增量迭代过程中,集合元素被修改,对返回值无法提供完全准确的保证。
- 如果一个元素是在迭代过程中被添加到数据集的, 又或者是在迭代过程中从数据集中被删除的, 那么这个元素可能会被返回, 也可能不会。
更多关于 Redis scan 命令的信息请查看 scan 命令。
提交订单后 Sku 何去何从
在购物车选中 sku 提交订单之后,这些 sku 将从购物车移除。
参考资料
总结
SpringBoot的知识已经有前辈在我们之前探索了。比较喜欢的博主有:唐亚峰 | Battcn、方志朋的专栏、程序猿DD、纯洁的微笑。对这门技术感兴趣的可以去他们的博客逛逛。谢谢他们的分享~~
以上文章是我用来学习的Demo,都是基于 SpringBoot2.x 版本。
源码地址: https://github.com/ynfatal/springboot2-learning/tree/master/chapter29